IDEA连接github,上传项目
IDEA中进行git和github的相关配置


创建本地仓库
VCS –>Import into Version Control –>Create Git Repository –>选择项目文件夹
上传工程
VCS –>Import into Version Control –>Share Project On GitHub–>填写名称和描述
进行修改上传操作
遵循git的方式:先add后commit最后push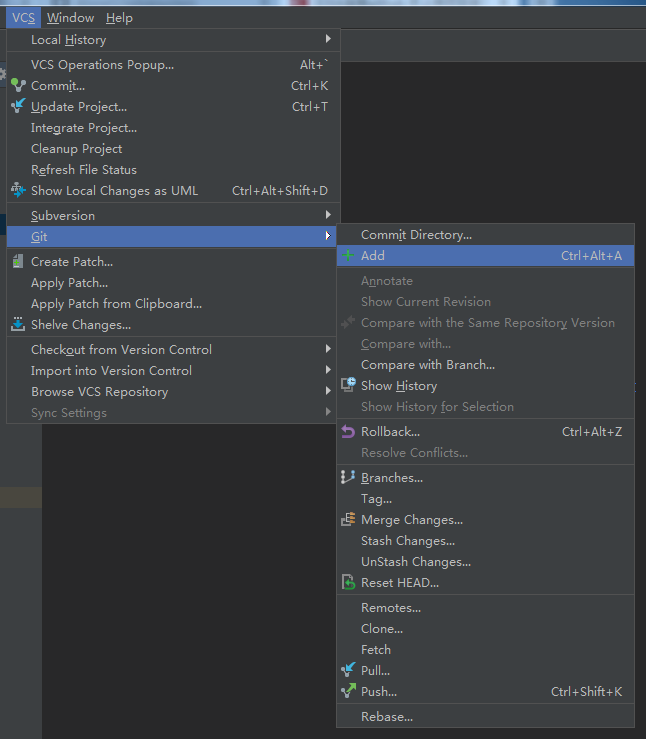
补充,更新操作
1 | public class cmd { |
1 | public class qumf { |
1 | /** |

int类型 0~10:
1 | 00000000 00000000 00000000 00000000 |
案例:
1 | public static void main(String[] args) { |

案例:
1 | public static void main(String[] args) { |
什么是补码: 将固定位数2进制数字, 分一半作为负数使用的编码规则。
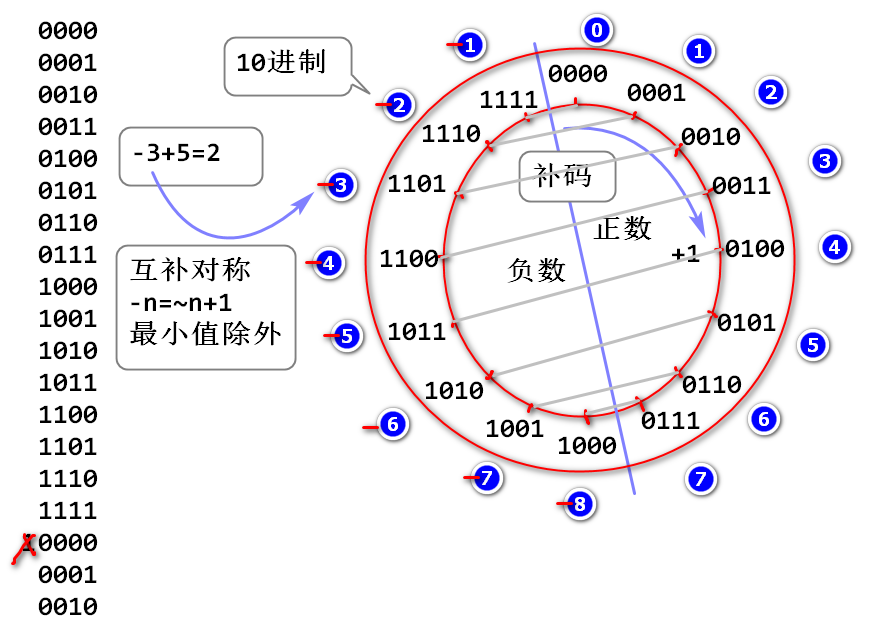
案例:补码的最大值和最小值
1 | public static void main(String[] args) { |
负数的补码:
1 | public static void main(String[] args) { |
先记住-1的补码,然后通过计算一个负数编码 比-1少多少个1 来得到其10进制值
补码的互补对称:
1 | 00000000 00000000 00000000 01010000 80 原码 |
案例:
1 | public static void main(String[] args) { |
运算符:1
2
3
4
5
6
7
81. ~ 取反
2. & 与计算机 (逻辑乘法, 有0则0)
- 通过'&'计算结果中存储的是数字n的最后8位数,称为掩码计算。其最终的结果是将 整数n的最后一个字节拆分出来。
3. | 或 (逻辑加法 有1则1)
- 通常将数字n和m拼接在一起
4. >>> 右移位 (将2进制数整体向右移动,低位自动溢出舍弃,高位补0)
5. >> 数学右移位
6. << 左移位 (将2进制数字整体向左移动,高位自动溢出,低位补0)
示例:1
2
3
4
5
6
7
8
9
10
11
12 b1 b2 b3 b4
n = 01110100 11111101 01001011 10101111
b1=(n>>>24)&0xff 00000000 00000000 00000000 01110100
n>>>16 00000000 00000000 01110100 11111101
b2=(n>>>16)&0xff 00000000 00000000 00000000 11111101
n>>>8 00000000 01110100 11111101 01001011
b3=(n>>>8)&0xff 00000000 00000000 00000000 01001011
b4=n&0xff 00000000 00000000 00000000 10101111
代码:1
2
3
4
5
6int n = 0x74fd4baf;
int b1 = (n>>>24) & 0xff;
int b2 = (n>>>16) & 0xff;
int b3 = (n>>>8) & 0xff;
int b4 = n & 0xff;
//验证
示例:
1 | n= 01110111 10101011 10100100 00011111 |
用途:将4个byte拼接为int
1 | b1 = 00000000 00000000 00000000 10110101 |
代码:将4个byte合并为一个int
1 | int b1 = 0xb5; |
10移动小数点计算:
1 | 十进制数 191321. |
2进制移位计算,向左移动一次扩大2倍
1 | n = 00000000 00000000 00000000 00110010 50 |
>>> 与 >>的区别>>> 逻辑右移位,2进制数字整体向右移动,低位溢出,高位补0 >> 数学右移位,2进制数字整体向右移动,低位溢出,负数补1,正数补0,运算结果相当数学除法,除以2向小方向取整数。
>>> 与 >>的区别: >>>就是将数字整体向右移动,不考虑数学结果,适用于单纯数据移位拆分等计算。 >>用于替代数学计算,达到提高运算性能的目的。
SpringBoot是默认整合了Spring、SpringMVC及相关常用框架的一个综合性框架,大量的减少了相关的配置,使得创建项目和使用变得更加简单。
在常规配置方面,SpringBoot的思想是“约定大于配置”,即:大多数开发者都会使用某种配置方式的话,则SpringBoot就会直接配置成那个样子,然后,开发者在使用SpringBoot时就不用再进行相关配置,只需要知道已经被配置完成了!
打开浏览器,访问https://start.spring.io/,填写创建项目的参数,配置完成后,点击Generate the project即可生成项目。
得到压缩文件解压后,通过EclipseImport 中 Exsiting Maven Projects导入该项目,务必保证当前可以连接到Maven服务器,导入后,会自动下载大量依赖,直至项目结构完整。
在resources下默认存在名为static的文件夹,该文件是SpringBoot项目用于存放静态资源的文件夹,例如(.html文件、图片、.css文件、.js文件等)相当于传统项目中的webapp文件夹,则可以在static创建index.html欢迎页面。
在java栏下默认存在cn.tedu.springboot.sample包,该包名是根据创建项目时的参数决定的,这个包就是当前项目的根包(Base-Package),并且在该包下已经存在SampleApplication.java文件,该文件的名称也是根据创建项目时填写的artifact决定的,该文件中包含main()方法,直接执行main()方法就可以启动当前项目,所以,该类也是SpringBoot的启动类!
SpringBoot项目在启动时会启动内置的Tomcat,默认占用8080端口,如果此前该端口已经处于占用状态,则项目会启动失败!
通过http://localhost:8080即可访问所涉及的网页,由于SpringBoot项目内置Tomcat,该Tomcat只为当前项目服务,所以启动时设置的Context Path是空字符串,在访问时URL中不必添加项目名称,而index.html是默认的欢迎页面,其文件名也不必体现在URL中!
SpringBoot项目默认没有集成持久层相关依赖,需要手动补充,或者创建项目时选中:
1 | <dependency> |
当添加以上依赖之后,SpringBoot项目再启动时就会尝试读取连接数据库的相关配置。
如果还没有配置,则会启动失败!
在resources下有application.properties,该文件就是SpringBoot的配置文件,在该文件中添加数据库相关配置:
1 | spring.datasource.url=jdbc:mysql://localhost:3306/tedu_ums?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai |
一般情况下,不需要配置连接数据库的driverClassName,因为SpringBoot会自动从jar中读取!
添加以上配置后,项目可以正常启动,但是,如果以上配置信息是错误的(格式错误除外),也不影响启动过程,也就是说,SpringBoot启动时,会读取相关配置,但是,并不执行数据库连接,所以,就算是配置错误也并不会体现出来。
在src/test/java下,默认已经存在项目的根包及测试类,且测试类中已经存在一个空的测试方法:
1 | (SpringRunner.class) |
可以先执行以上
contextLoads()方法的单元测试,如果测试出错,一定是测试环境或者框架环境有问题,多考虑为jar包已经损坏,应该重新下载或者更换版本!
可以在该测试类中编写单元测试:
1 |
|
至此,测试通过,此前配置数据库连接信息是正确的!
先创建与数据表对应的实体类cn.tedu.springboot.sample.entity.User:
1 | public class User implements Serializable { |
然后,创建持久层接口cn.tedu.springboot.sample.mapper.UserMapper:
1 | public interface UserMapper { |
为了保证MyBatis框架能确定接口文件的位置,可以在接口的声明之前添加@Mapper注解,不过,这样的做法就要求每一个持久层接口之前都需要添加该注解,也可以在启动类SampleApplication之前添加@MapperScan注解进行配置,则后续只需要把持久层接口都放在这个包中就可以了,无需反复添加注解:
1 |
|
1 | (useGeneratedKeys=true, keyProperty="id") |
这种做法是MyBatis本身就支持的,并不是SpringBoot所特有的!这种做法最大的优点在于:对应关系非常直观。
主要的缺陷在于:配置长篇的SQL语句时,代码不易于阅读和维护!所以,一般仍然推荐使用XML配置映射的SQL语句!
1 |
|
另外,还需要配置XML文件的位置,则打开application.properties文件添加配置:
1 | mybatis.mapper-locations=classpath:mappers/*.xml |
在src/test/java下创建新的cn.tedu.springboot.sample.mapper.UserMapperTests单元测试类,将默认存在的SampleApplicationTests类之前的2行注解复制到UserMapperTests类之前:
1 | (SpringRunner.class) |
然后,在类中声明持久层对象的属性:
1 | (SpringRunner.class) |
凡是以前在SSM项目中可以通过
getBean()方式获取的对象,在SpringBoot项目中都可以使用自动装配!
然后,编写并执行测试方法:
1 | (SpringRunner.class) |
先创建控制器处理请求后的返回结果对象的类型cn.tedu.springboot.sample.util.JsonResult:
1 | public class JsonResult { |
SpringBoot项目不需要开发者配置组件扫描,它默认的组件扫描就是项目的根包,即cn.tedu.springboot.sample包,当前项目中所有的组件都必须在这个包或者其子包下!
所以,创建cn.tedu.springboot.sample.controller.UserController控制器类,在类之前添加@RestController注解和@RequestMapping("user")注解:
1 |
|
使用
@RestController相当于@Controller和@ResponseBody的组合使用方式,当使用了@RestController时,该控制器类中所有处理请求的方法都是相当于添加了@ResponseBody注解!一旦使用了该注解,该控制器类中的方法将不可以转发或者重定向,如果一定要转发或者重定向,必须使用ModelAndView作为处理请求的方法的返回值!
然后,在控制器类中添加处理请求的方法:
1 | // /user/reg |
在SpringBoot项目中,默认已经将
DispatcherServlet映射的路径配置为/*,即所有请求。
在处理过程中,显然需要使用到持久层对象来完成数据操作,所以,应该声明持久层对象的属性:
1 |
|
然后,完成处理请求的细节:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24("reg")
public JsonResult reg(User user) {
// 创建返回值对象
JsonResult jsonResult = new JsonResult();
// 从参数user中获取尝试注册的用户名
String username = user.getUsername();
// 根据以上用户名查询用户数据
User result = userMapper.findByUsername(username);
// 检查查询结果是否为null
if (result == null) {
// 是:用户名未被占用
// 执行注册
userMapper.insert(user);
// 封装返回值对象的属性:1
jsonResult.setState(1);
} else {
// 否:用户名已经被占用
// 封装返回值对象的属性:2, 错误提示信息
jsonResult.setState(2);
jsonResult.setMessage("注册失败!尝试注册的用户名(" + username + ")已经被占用!");
}
// 返回
return jsonResult;
}
完成后,通过启动类启动项目,打开浏览器,输入:http://localhost:8080/user/reg?username=junit&password=1234进行测试。
AJAX即“Asynchronous JavaScript and XML”(异步的 JavaScript 与 XML 技术),指的是一套综合了多项技术的浏览器端网页开发技术。Ajax的概念由杰西·詹姆士·贾瑞特所提出。
传统的Web应用允许用户端填写表单(form),当提交表单时就向网页服务器发送一个请求。服务器接收并处理传来的表单,然后送回一个新的网页,但这个做法浪费了许多带宽,因为在前后两个页面中的大部分 HTML 码往往是相同的。由于每次应用的沟通都需要向服务器发送请求,应用的回应时间依赖于服务器的回应时间。这导致了用户界面的回应比本机应用慢得多。
与此不同,AJAX应用可以仅向服务器发送并取回必须的数据,并在客户端采用JavaScript处理来自服务器的回应。因为在服务器和浏览器之间交换的数据大量减少,服务器回应更快了。同时,很多的处理工作可以在发出请求的客户端机器上完成,因此Web服务器的负荷也减少了。
类似于DHTML,AJAX不是指一种单一的技术,而是有机地利用了一系列相关的技术。虽然其名称包含XML,但实际上数据格式可以由JSON代替,进一步减少数据量,形成所谓的AJAJ。而客户端与服务器也并不需要异步。一些基于AJAX的“派生/合成”式(derivative/composite)的技术也正在出现,如AFLAX。
传统的响应方式有转发和重定向,这样的做法有很多问题,比如:转发和重定向都决定了响应的具体页面,不适合多种客户端(浏览器、Android手机、Android平板电脑、iOS手机、iOS平板电脑……)的项目,因为不同的终端设备的性能特征是不一样的,把同样的一个页面都显示给不同的终端设备是极不合适的!正确的做法应该是“服务器端只响应客户端所需要的数据”,至于这些数据如何呈现在终端设备中,由各客户端的开发团队去解决!
如果使用响应正文的方式,还存在“响应数据量小”的优势,则响应速度更快,产生的流量消耗小,用户体验好!
假设客户端会提交http://localhost:8080/AJAX/user/login.do请求,如果需要响应方式是“响应正文”,则需要在处理请求的方法之前补充添加@ResponseBody注解:1
2
3
4
5
6
7
8
9
10
("user")
public class UserController {
("login.do")
public String login() {
return "LOGIN SUCCESS.";
}
}
默认情况下,响应的内容使用了ISO-8859-1编码,所以,不支持中文。
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
通常,服务器向客户端响应的数据可能不只是1个数据,以登录操作为例,也许可以响应为1表示登录成功,使用2表示登录失败且是因为用户名错误,使用3表示密码错误,则客户端就可以通过对这个值的判断,得知当前操作结果,但是,其它操作可能会需要更多的数据,例如“客户端尝试获取当前登录的用户信息”,需要响应的数据可能包括:用户名、手机号码、电子邮箱、年龄等一系列数据,由于响应结果只是1个字符串,要把这些数据很好的组织起来,才可以方便客户端从这1个字符串中获取其中某部分的数据,否则,如果只是响应为"root13800138001root@163.com26"这样,客户端就无法处理这个响应结果。
早期通常使用XML语法来组织这些数据:
1 | <user> |
使用XML存在的问题:
目前推荐使用的组织数据的格式是JSON格式,以上数据使用JSON组织后的表现为:
1 | { |
JSON数据在Javascript中是默认即识别的对象,可以直接得到其中的属性值:
1 | <script type="text/javascript"> |
关于JSON数据格式:
{}表示对象,整个JSON数据就是1个对象;:分隔,多个属性的配置之间使用逗号,分隔;[]框柱数组的各元素,各元素之间使用逗号,分隔,在JavaScript中处理时,使用例如json.skill就可以获取到整个数组,使用json.skill.length就可以获取数组的长度,使用json.skill[0]就可以获取数组中下标为0的元素,也可以使用循环语法进行循环;{}表示对象。如果在JavaScript中,得到是一个使用JSON语法组织的字符串,而不是JSON对象,可以调用JSON.parse(str)函数,将字符串转换为JSON对象。
如果需要服务端响应JSON格式的数据,不可能自行拼接出JSON格式的字符串,可以通过工具来解决
jackson-databind的依赖:1 | <dependency> |
在项目中自定义cn.tedu.ajax.JsonResult响应结果类型
并修改处理请求的方法,返回值类型使用以上自定义的类型:
1 | ("login.do") |
1 | <!-- 注解驱动 --> |
然后,控制器中处理请求的方法响应的正文就是JSON格式的字符串。
在控制器中响应正文时,需要添加@ResponseBody注解,SpringMVC框架内置了一系列的转换器(Converter),用于将方法的返回值转换为响应的正文,在这一系列的转换器中,SpringMVC设计了对应关系和优先级,例如,当方法的返回值类型是String时,就会自动调用StringHttpMessageConverter,当项目中添加了jackson-databind依赖时,如果方法的返回值类型是SpringMVC默认不识别的,就会自动使用Jackson依赖中的转换器!Jackson依赖还会将响应头(Response Headers)中的Content-Type设置为application/json, charset=utf-8。
小结:需要自定义数据类型,以决定响应的JSON数据格式(有哪些属性,分别是什么类型),然后用自定义类型作为方法的返回值,并处理完成后返回该类型的对象,Jackson依赖就会自动的设置为支持中文,且把响应的对象转换成JSON字符串。
在实际实现时,通常是基于jQuery框架实现AJAX访问,主要是因为原生技术的代码比较繁琐,且存在浏览器的兼容性问题,在jQuery中,定义了$.ajax()函数,用于处理AJAX请求,调用该函数即可实现异步访问:
1 | <script type="text/javascript" src="jquery-3.4.1.min.js"></script> |
在设计查询的抽象方法时:
null。例如:根据用户id查询用户数据详情时:1
User findById(Integer id);
在配置该方法的XML映射时,使用的<select>节点必须配置resultType或者resultMap属性中的某一个:1
2
3
4<select id="findById"
resultType="cn.tedu.mybatis.User">
SELECT * FROM t_user WHERE id=#{id}
</select>
例如:获取当前数据表用户数据的数量:1
Integer count();
映射配置为:1
2
3
4<select id="count"
resultType="java.lang.Integer">
SELECT COUNT(*) FROM t_user
</select>
例如:查询所有用户数据时:1
List<User> findAll();
配置的映射:1
2
3
4<select id="findAll"
resultType="cn.tedu.mybatis.User">
SELECT * FROM t_user ORDER BY id ASC
</select>
假设需要实现:将id=?的用户的密码修改为?,则抽象方法:1
Integer updatePasswordById(Integer id, String newPassword);
配置xml中的映射:1
2
3<update id="updatePasswordById">
UPDATE t_user SET password=#{newPassword} where id=#{id}
</update>
如果直接执行以上代码,会报告错误:
可以在抽象方法的每一个参数之前添加@Param注解,MyBatis框架在处理时,会将这些参数封装成1个Map,依然能满足“只能识别1个参数”的需求,后续在配置XML映射时,使用的#{}占位符中的名称就必须是注解中配置的名称,表示的是MyBatis自动封装的Map中的Key:1
2
3Integer updatePasswordById(
@Param("id") Integer arg0,
@Param("password") String arg1);
配置的XML映射:1
2
3<update id="updatePasswordById">
UPDATE t_user SET password=#{password} where id=#{id}
</update>
小结:如果涉及的抽象方法的参数达到2个甚至更多,则每个参数之前都必须添加@Param注解,并在注解中指定名称,后续配置XML映射时,使用的#{}中的名称也是注解中配置的名称!
MyBatis中的动态SQL指的是根据参数不同,动态的生成不同的SQL语句。
例如:根据若干个id删除用户数据,设计的抽象方法:1
Integer deleteByIds(List<Integer> ids);
配置映射:1
2
3
4
5
6
7
8
9
10
11
12
13<delete id="deleteByIds">
DELETE FROM
t_user
WHERE
id
IN
(
<foreach collection="list"
item="id" separator=",">
#{id}
</foreach>
)
</delete>
在配置<foreach>节点时:
collection:被遍历的参数对象,首先,如果对应的抽象方法的参数只有1个时,如果参数是List集合类型的,取值为list,如果参数是数组类型的,取值为array,另外,如果对应的抽象方法的参数有多个,则每个参数肯定都添加了@Param注解,此处需要配置的值就是注解中配置的名称;item:遍历过程中获取到的数据的名称,相当于增强for循环的语法中,括号中的第2个部分,在<foreach>节点的子级可以使用#{}占位符,占位符中的名称就是item属性的值;separator:遍历过程中各元素使用的分隔符;open和close:遍历产生的代码的最左侧字符和最右侧字符。假设存在抽象方法:1
List<User> find(String where, String orderBy, Integer offset, Integer count);
在配置SQL语句时,可以使用if标签进行对参数的判断,从而产生不同的SQL语句的某个部分,例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<select id="xx" resultType="xx.xx.xx.User">
SELECT
*
FROM
t_user
<if test="where != null">
WHERE
#{where}
</if>
<if test="orderBy != null">
ORDER BY
#{orderBy}
</if>
<if test="offset != null">
LIMIT
#{offset}, #{count}
</if>
</select>
以上配置是错误的,并不能所有位置都使用#{}占位符,有几处需要使用${}格式的占位符:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<select id="find"
resultType="cn.tedu.mybatis.User">
SELECT
*
FROM
t_user
<if test="where != null">
WHERE
${where}
</if>
<if test="orderBy != null">
ORDER BY
${orderBy}
</if>
<if test="offset != null">
LIMIT
#{offset}, #{count}
</if>
</select>
在MyBatis中,编写XML中的SQL语句时,可以使用#{}格式的占位符,还可以使用${}格式的占位符!
MyBatis在处理有占位符的SQL时,如果是${}格式的占位符,会先通过字符串拼接的方式把变量值替换并拼接出SQL语句,然后尝试编译该SQL语句,如果是#{}格式的占位符,会使用?进行占位并尝试编译,编译过后再使用值进行替换。
使用JDBC时,可以使用
?表示的部分,都应该使用#{},也可以理解为只有“值”才可以使用#{},这种做法是预编译的,否则,如果要对SQL语句中的某个子句或者其他语句的某个部分,甚至是WHERE子句中的表达式,使用${},这种做法并不会预编译。
修改t_user表结构,添加名为is_delete的字段:1
2
3alter table t_user add column is_delete int;
update t_user set is_delete=0;
对应的User类中也需要添加对应的属性,在Java中,不推荐在变量名中使用_符号,所以,添加属性为·isDelete。
由于名称不是完全相同了,所以,此前的查询功能就无法查询出数据的
is_delete字段的值!
MyBatis封装查询结果的标准就是“将查询到的数据封装到与列名完全相同的属性中”,所以,如果字段名与属性名不一致,就会导致默认的列名与属性名不一致,可以在查询时,为列名自定义别名,以保持名称一致,所以,解决方案可以是:1
2
3
4
5
6
7
8
9SELECT
id, username,
password, age,
phone, email,
is_delete AS isDelete
FROM
t_user
ORDER BY
id ASC
如果在查询时,使用*表示要查询的字段列表,MyBatis就无法自动封装那些名称不一致的数据,可以在XML文件配置<resultMap>节点,并且在查询的<select>节点中,使用resultMap属性取代resultType属性:
1 | <!-- resultMap节点:指导MyBatis如何封装查询结果 --> |
小结:无论是取别名,还是配置
<resultMap>,只要能保证MyBatis知道如何封装名称不一致的数据,就可以正确查询到所需要的结果!如果查询时不用/*表示字段列表,且名称不一致的字段较少,则可以优先考虑使用别名,如果使用/*查询,或者名称不一致的字段较多,则应该优先考虑配置<resultMap>。
创建t_department部门信息表,要求表中存在id和name这2个字段,向表中插入3条数据:1
2
3
4
5
6
7CREATE TABLE t_department (
id INT AUTO_INCREMENT COMMENT '部门id',
name VARCHAR(50) NOT NULL UNIQUE COMMENT '部门名称',
PRIMARY KEY (id)
) DEFAULT CHARSET=UTF8;
INSERT INTO t_department (name) VALUES ('软件研发部'), ('人力资源部'), ('财务部');
在t_user表中添加department_id字段,为每一个用户数据分配部门id:1
2
3
4
5ALTER TABLE t_user ADD COLUMN department_id INT;
UPDATE t_user SET department_id=1 WHERE id IN (2,10,17);
UPDATE t_user SET department_id=2 WHERE id IN (16,14,12);
UPDATE t_user SET department_id=3 WHERE id IN (4,13);
假设存在需求:根据id查询某用户详情,要求直接显示用户所在部门的名称。
首先,直接查询t_user表是不足以得到完整答案的,为了保证数据表管理的规范,在t_user表中只会存储部门的id,并不会存储部门的name,所以,需要实现该需求,就必须使用关联查询:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15SELECT
t_user.id, username,
phone, email,
password, age,
is_delete AS isDelete,
department_id AS departmentId,
name AS departmentName
FROM
t_user
LEFT JOIN
t_department
ON
department_id=t_department.id
WHERE
t_user.id=?
这样的查询可以符合当前需求,但是,在设计代码时,却没有任何一个实体类可以封装以上查询结果!因为实体类都是与数据表一一相对应的,所以就需要另外创建VO(Value Object)类,VO类的设计原则是根据查询结果来确定各属性的:1
2
3
4
5
6
7
8
9
10
11
12public class UserVO {
private Integer id;
private String username;
private String password;
private Integer age;
private String phone;
private String email;
private Integer isDelete;
private Integer departmentId;
private String departmentName;
// SET/GET/hashCode/equals/toString/Serializable
}
其实,VO类与实体类的设计方式是几乎一样的,只是定位不同,实体类与数据表对应,VO类与查询结果对应。
设计的抽象方法的返回值就应该是UserVO:
1 | UserVO findUserVOById(Integer id); |
配置映射时,需要注意自定义别名,或者配置<resultMap>,同时,注意:如果某个字段名在2张或者涉及的多张表中都存在,必须明确的指定表名,例如这2张表中都有id字段,每次涉及该字段都必须在左侧指定表名:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<select id="findUserVOById"
resultType="cn.tedu.mybatis.UserVO">
SELECT
t_user.id, username,
phone, email,
password, age,
is_delete AS isDelete,
department_id AS departmentId,
name AS departmentName
FROM
t_user
LEFT JOIN
t_department
ON
department_id=t_department.id
WHERE
t_user.id=#{id}
</select>
简化数据库编程,开发者只要指定每项数据操作时的SQL语句及对应的抽象方法即可。
创建Maven Project,添加需要的依赖:1
2
3
4
5<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.1</version>
</dependency>
MyBatis框架是可以独立使用的,但是配置相对繁琐,且没有实际价值,通常都是与Spring结合使用的,甚至结合了SpringMVC,所以,需要添加mybatis-spring的依赖:
1 | <dependency> |
MyBatis的底层是基于jdbc实现的,所以,结合Spring使用后,需要添加spring-jdbc依赖,该依赖的代码与spring-webmvc几乎一样,只是artifact id不同,通常,这2个依赖的版本应该完全相同:
1 | <dependency> |
还需要添加mysql-connector-java的依赖:
1 | <dependency> |
另外,还需要commons-dbcp数据库连接池的依赖:
1 | <dependency> |
最后,还需要添加单元测试
junit依赖。
创建db.properties文件,以确定数据库连接的相关配置:1
2
3
4
5
6url=jdbc:mysql://localhost:3306/tedu_ums?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
driver=com.mysql.cj.jdbc.Driver
username=root
password=root
initialSize=2
maxActive=5
在Spring的配置文件中读取properties配置信息:1
2
3<!-- 读取db.properties -->
<util:properties id="dbConfig"
location="classpath:db.properties" />
程序运行时,需要使用的数据源是BasicDataSource,框架会通过这个类的对象获取数据库连接对象,然后实现数据访问,所以,就需要为这个类的相关属性注入值,把数据库配置信息确定下来:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<!-- 配置数据源 -->
<bean id="dataSource"
class="org.apache.commons.dbcp.BasicDataSource">
<property name="url"
value="#{dbConfig.url}" />
<property name="driverClassName"
value="#{dbConfig.driver}" />
<property name="username"
value="#{dbConfig.username}" />
<property name="password"
value="#{dbConfig.password}" />
<property name="initialSize"
value="#{dbConfig.initialSize}" />
<property name="maxActive"
value="#{dbConfig.maxActive}" />
</bean>
检验以上完成的配置是否正确,创建测试类,编写并执行测试方法:1
2
3
4
5
6
7
8
9
10
11
12
public void getConnection() throws SQLException {
ClassPathXmlApplicationContext ac
= new ClassPathXmlApplicationContext("spring.xml");
BasicDataSource ds = ac.getBean("dataSource", BasicDataSource.class);
Connection conn = ds.getConnection();
System.out.println(conn);
ac.close();
}
创建cn.tedu.mybatis.User类,类的属性与t_user表保持一致:1
2
3
4
5
6
7
8
9
10
11
12public class User {
private Integer id;
private String username;
private String password;
private Integer age;
private String phone;
private String email;
// SET/GET/toString/hashCode/equals/Serializable
}
在MyBatis中,要求抽象方法写在接口中,所以,需要先创建cn.tedu.mybatis.UserMapper接口,然后,在接口中添加抽象方法,设计原则:
INSERT/UPDATE/DELETE,返回值类型使用Integer,表示受影响的行数;对于要执行的数据操作,先完成“增加”操作,则添加关于“增加”用户数据的抽象方法:1
Integer insert(User user);
然后,需要通过配置,是让MyBatis框架知道接口在哪里,所以,在Spring的配置文件中添加配置:
1 | <!-- 配置MapperScannerConfigurer --> |
下载mybatis-mapper.zip文件,在项目的resources下创建mappers文件夹,将得到的xml文件复制到mappers文件夹中,并重命名为UserMapper.xml。
然后在该文件中配置SQL语句:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<!-- namespace:当前XML文件用于配置哪个接口中抽象方法对应的SQL语句 -->
<mapper namespace="cn.tedu.mybatis.UserMapper">
<!-- 使用insert节点配置插入数据的SQL语句 -->
<!-- id:抽象方法的方法名 -->
<!-- 在#{}中间的是方法的参数User类中的属性名称 -->
<insert id="insert">
INSERT INTO t_user (
username, password,
age, phone,
email
) VALUES (
#{username}, #{password},
#{age}, #{phone},
#{email}
)
</insert>
</mapper>
最后,需要在Spring的配置文件补充配置,使得MyBatis框架知道这些XML文件在哪里,且执行时使用的数据源是哪一个:1
2
3
4
5
6
7
8
9<!-- SqlSessionFactoryBean -->
<bean class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- XML文件在哪里 -->
<property name="mapperLocations"
value="classpath:mappers/*.xml" />
<!-- 使用哪个数据源 -->
<property name="dataSource"
ref="dataSource" />
</bean>
完成后,在测试类中编写并执行单元测试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public void insert() {
ClassPathXmlApplicationContext ac
= new ClassPathXmlApplicationContext(
"spring.xml");
UserMapper userMapper
= ac.getBean("userMapper", UserMapper.class);
System.out.println(userMapper.getClass());
User user = new User();
user.setUsername("admin");
user.setPassword("1234");
Integer rows = userMapper.insert(user);
System.out.println("rows=" + rows);
ac.close();
}
在配置<insert>节点时,添加useGeneratedKeys="true"和keyProperty="id"的配置:1
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
然后,执行数据操作后,方法的参数对象中就会被封装自动编号的id值!
以上配置的2个属性,useGeneratedKeys表示“要不要获取自动生成的字段的值,即自动编号的值”,keyProperty表示“获取到的自动编号的值封装在参数对象的哪个属性中”,所以,在本例中,指的是User类中的id属性,并不是t_user表中的id字段。
通常,Property单词表示“属性”,类才有属性,数据表没有属性,Field表示“字段”,仅当描述数据表结构时才称之为字段,Column表示“列”,仅当描述查询结果时才称之为列。
可以在处理请求的方法中,添加HttpServletRequest类型的参数,在处理过程中,调用该参数对象的String getParameter(String name)就可以获取请求参数。
不推荐使用这种做法!主要原因有:
假设客户端将提交名为username的参数,则在控制器的方法中添加同名参数即可,参数的类型可以是期望的数据类型,例如username是String类型的,则声明为String username即可:1
2
3
4
5
6
7("handle_reg.do")
public String handleReg(String username, String password) {
System.out.println("UserController.handleReg()");
System.out.println("\t[2]username=" + username);
System.out.println("\t[2]password=" + password);
return null;
}
null值。HttpServletRequest获取参数时的所有问题!当客户端提交的请求参数较多时,可以将这些参数全部封装为1个自定义的数据类型,例如:1
2
3
4
5
6
7
8
9public class User {
private String username;
private String password;
private Integer age;
private String phone;
private String email;
//生成GET、SET方法和toString
}
将该类型作为处理请求的方法的参数即可:1
2
3
4
5
6("handle_reg.do")
public String handleReg(User user) {
System.out.println("UserController.handleReg()");
System.out.println("\t" + user);
return null;
}
在使用这种做法时,需要保证客户端提交的请求参数,与自定义的数据类型中的属性名称是保持一致的!
第1种使用HttpServletRequest的方式是不会再使用的。
如果请求参数的数量较少,且从业务功能来说参数的数量基本固定,推荐使用第2种方式,即直接将请求参数逐一的设计在处理请求的方法中,否则,就使用第3种方式,将多个参数封装成1个自定义的数据类型。
另外,第2种方式和第3种方式是可以组合使用的,即出现在同一个处理请求的方法中!
当处理请求的方法的返回值是String类型的,则返回的字符串使用redirect:作为前缀,加上重定向的目标路径,就可以实现重定向的效果。
假设注册一定成功,且注册成功后需要跳转到登录页面,则:1
2
3
4
5
6
7
8
9
10("handle_reg.do")
public String handleReg(User user) {
System.out.println("UserController.handleReg()");
System.out.println("\t" + user);
// 注册成功,重定向到登录页
// 当前位置:handle_reg.do
// 目标位置:login.do
return "redirect:login.do";
}
当处理请求的方法的返回值是String类型,默认情况下,返回值就表示转发的意思,返回值将经过视图解析器,确定转发到的目标页面。
转发时,处理请求的方法的返回值也可以使用forward:作为前缀,由于默认就是转发,所以不必显式的添加前缀。
假设在登录过程中,仅当用户名为root且密码是1234时允许登录,否则,在错误提示页面中提示错误的原因。
由于错误信息可能有2种,分别是用户名错误和密码错误,使用JSP页面结合EL表达式可以显示转发的数据,在控制器转发之前,就需要将错误信息封装到HttpServletRequest对象中,则后续JSP页面才可以通过EL表达式读取HttpServletRequest对象中的数据。
可以在处理请求的方法的参数列表中添加HttpServletRequest类型的参数,当添加了参数后,调用HttpServletRequest参数对象的setAttribute(String name, String value)方法封装需要转发的数据即可,无需获取转发器对象执行转发,只要最后返回字符串就表示转发:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21("handle_login.do")
public String handleLogin(String username, String password,
HttpServletRequest request) {
// 判断用户名是否正确
if ("root".equals(username)) {
// 是:判断密码是否正确
if ("1234".equals(password)) {
// 是:登录成功,重定向到主页
return "redirect:index.do";
} else {
// 否:密码错误
request.setAttribute("errorMessage", "密码错误");
return "error";
}
} else {
// 否:用户名错误
request.setAttribute("errorMessage", "用户名错误");
return "error";
}
}
这种做法依然是不推荐的,使用了
HttpServletRequest作为参数后不便于执行单元测试。
使用ModelAndView作为处理请求的方法的返回值类型,在返回结果之前,调用ModelAndView对象的setViewName(String viewName)方法确定转发的视图名称,调用addObject(String name, Object value)方法封装需要转发的数据,然后返回结果即可:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23("handle_login.do")
public ModelAndView handleLogin(String username, String password) {
// 创建返回值对象
ModelAndView mav = new ModelAndView();
// 判断用户名是否正确
if ("root".equals(username)) {
// 是:判断密码是否正确
if ("1234".equals(password)) {
// 是:登录成功,重定向到主页
return null;
} else {
// 否:密码错误
mav.addObject("errorMessage", "ModelAndView:密码错误");
mav.setViewName("error");
return mav;
}
} else {
// 否:用户名错误
mav.addObject("errorMessage", "ModelAndView:用户名错误");
mav.setViewName("error");
return mav;
}
}
因为对于初学SpringMVC的人来说,
ModelAndView是一个新的、比较麻烦的数据类型,并且SpringMVC提供了更简单的操作方式,所以不推荐使用ModelAndView。
使用ModelMap的方式与使用HttpServletRequest几乎完全相同:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21("handle_login.do")
public String handleLogin(String username, String password,
ModelMap modelMap) {
// 判断用户名是否正确
if ("root".equals(username)) {
// 是:判断密码是否正确
if ("1234".equals(password)) {
// 是:登录成功,重定向到主页
return "redirect:index.do";
} else {
// 否:密码错误
modelMap.addAttribute("errorMessage", "ModelMap:密码错误");
return "error";
}
} else {
// 否:用户名错误
modelMap.addAttribute("errorMessage", "ModelMap:用户名错误");
return "error";
}
}
相比HttpServletRequest而言,使用ModelMap更加易于实现单元测试,并且更加轻量级,所以,推荐使用这种方式来封装需要转发的数据。
练习:假设root是已经被注册的用户名,在处理注册时,如果用户提交的用户名是root,则提示错误,否则,视为注册成功,重定向到登录页。
在处理请求的方法之前添加@RequestMapping,可以配置请求路径与处理请求的方法的映射关系。
除此以外,还可以在控制器类之前添加该注解,表示增加了访问路径中的层级,例如:1
2
3
4
("user")
public class UserController {
}
添加该注解以后,原本通过login.do访问的请求路径就需要调整为user/login.do才可以访问。通常,推荐为每一个控制器类都添加该注解!同时在类和方法之前都添加了注解后,最终的访问路径就是类与方法的注解中的路径组合出来的URL。
在配置路径时,会无视两端的
/符号
在配置@RequestMapping时,可以显式的配置为:1
(value="reg.do")
该属性的数据类型是String[],也可以配置为:1
(value= {"reg.do", "register.do"})
则后续无论通过这里的哪个URL都会导致映射的方法被执行。
源代码中在value属性的声明上方还使用了@AliasFor注解,表示value和path是完全等效的!从SpringMVC 4.2版本开始支持使用path属性,并推荐使用path属性取代value属性。
在使用时,还可以指定method属性,该属性的作用是用于限制请求方式,例如:1
(path= {"reg.do", "register.do"}, method=RequestMethod.POST)
以上代码表示提交的请求必须是POST请求,如果不是,会导致405错误,在没有配置
method之前,是不限定请求方式的,如果配置了,则必须使用配置的请求方式中的某一种!当为注解配置多个属性时,每一个属性都必须显式的指定属性名称!
可以在处理请求的方法的参数之前添加@RequestParam注解,首先,使用该注解可以解决名称不一致的问题,即客户端提交的请求参数名称与服务器端处理请求的方法的参数名称不一致的问题,例如:1
("uname") String username
如果添加了该注解,仍然存在名称不一致的问题,会导致400错误(如果没有添加该注解,即使名称不一致,服务器端的参数只是null值,并不会报错)
原因在于在该注解的源代码中:1
boolean required() default true;
所以,添加了该注解,默认是必须提交指定名称的参数的!如果希望该请求参数不是必须提交的,可以:1
(name="uname", required=false) String username
该注解中还有:1
String defaultValue() default ValueConstants.DEFAULT_NONE;
该属性用于指定默认值,即客户端没有提交指定名称的参数时,默认为某个值,例如:1
(name="uname", required=false, defaultValue="admin") String username
注意:在设置默认值时,必须显式的将
required属性设置为false。
小结:在什么时候需要使用该注解?






